Kamagra gibt es auch als Kautabletten, die sich schneller auflösen als normale Pillen. Manche Patienten empfinden das als angenehmer. Wer sich informieren will, findet Hinweise unter kamagra kautabletten.
A semantic graph-based approach to biomedical summarisation


Contents lists available at
Artificial Intelligence in Medicine
A semantic graph-based approach to biomedical summarisation
Laura Plaza , Alberto Díaz, Pablo Gervás
Departamento de Ingeniería del Software e Inteligencia Artificial, Universidad Complutense de Madrid, C/Profesor José García Santesmases, s/n, 28040 Madrid, Spain
Objective: Access to the vast body of research literature that is available in biomedicine and related
Received 12 November 2009
fields may be improved by automatic summarisation. This paper presents a method for summarising
Received in revised form 10 May 2011
biomedical scientific literature that takes into consideration the characteristics of the domain and the
Accepted 18 June 2011
type of documents.
Methods: To address the problem of identifying salient sentences in biomedical texts, concepts and rela-
tions derived from the Unified Medical Language System (UMLS) are arranged to construct a semantic
graph that represents the document. A degree-based clustering algorithm is then used to identify dif-
Biomedical concept annotation
ferent themes or topics within the text. Different heuristics for sentence selection, intended to generate
Concept clustering
Unified Medical Language System
different types of summaries, are tested. A real document case is drawn up to illustrate how the method
Biomedical text summarisation
Results: A large-scale evaluation is performed using the recall-oriented understudy for gisting-evaluation
(ROUGE) metrics. The results are compared with those achieved by three well-known summarisers (two
research prototypes and a commercial application) and two baselines. Our method significantly outper-
forms all summarisers and baselines. The best of our heuristics achieves an improvement in performance
of almost 7.7 percentage units in the ROUGE-1 score over the LexRank summariser (0.7862 versus 0.7302).
A qualitative analysis of the summaries also shows that our method succeeds in identifying sentences
that cover the main topic of the document and also considers other secondary or "satellite" information
that might be relevant to the user.
Conclusion: The method proposed is proved to be an efficient approach to biomedical literature sum-
marisation, which confirms that the use of concepts rather than terms can be very useful in automatic
summarisation, especially when dealing with highly specialised domains.
2011 Elsevier B.V. All rights reserved.
without having to read the entire document can use
summaries to identify treatment options, reducing diagnosis time
It is undeniable that information technologies have repre-
automatic summaries have been shown to improve
sented a major milestone in health care practice and in biomedical
indexing and categorisation of biomedical literature when used as
research. New technologies, such as high-speed networks and mas-
substitutes for the articles' abstracts though the prob-
sive storage, along with the progressive adoption of the electronic
lem of information overload and the benefits of summarisation are
health record (EHR) and the increasing publication of research
common to most scientific disciplines, they are particularly criti-
results in digital journals, are supposed to improve work efficiency
cal in the biomedical domain because physicians and researchers
by assuring data persistence and the availability of information
require quick access to up-to-date information relevant to their
everywhere and at any time.
Access to biomedical literature has been shown to be benefi-
The majority of summarisation systems are designed to be
cial to both health professionals and consumers However,
general-purpose, and for this reason they do not take into account
the enormous volume of literature available threatens to under-
the particular properties of each domain and document type. They
mine the convenience of the information in the absence of easy and
usually work with a representation of the document consisting
effective access technologies summarisation may help
of information that can be directly extracted from the docu-
to manage this information overload Researchers can use
ment itself, such as terms, phrases or sentences
summaries to quickly determine whether an article is of interest
recent studies have demonstrated the benefits of summarisation
based on richer representations that make use of domain-specific
knowledge sources approaches represent the documents
∗ Corresponding author. Tel.: +34 91 394 7576; fax: +34 91 394 7547.
using concepts instead of words, and they may also be enriched
E-mail addresses: (L. Plaza).
by using semantic associations among concepts (e.g., synonymy,
0933-3657/$ – see front matter
2011 Elsevier B.V. All rights reserved.
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
hypernymy, homonymy or co-occurrence) to improve the quality of
are usually combined using a linear weighting function that assigns
the summaries. In particular, the Unified Medical Language System
a single score to each sentence in the document, and the high-
(UMLS) proved to be a useful knowledge source for sum-
est scoring sentences are extracted for the summary. More recent
marisation in the biomedical domain the need to
approaches also employ machine learning techniques to determine
consider the particular characteristics of the domain and the type of
the best subset of features for extraction
documents is becoming apparent. First, documents in biomedicine
Most advanced techniques incorporate graph-based methods.
are very different from documents in other fields and include very
This paper mainly investigates previous work in graph-based
different document types (e.g., patient records, web documents,
summarisation (see a more thorough study of domain-
scientific papers and even e-mailed reports). Second, medical lan-
independent summarisation techniques and biomedical-
guage, despite being highly specialised, is also highly interpretive,
focused approaches). Graph-based methods usually represent the
and it is constantly expanding seems reasonable that these
documents as graphs where the nodes correspond to text units such
peculiarities should be exploited by the summarisation system.
as words, phrases, sentences or even paragraphs, and the edges rep-
The main contribution of this work is to show how the use of
resent cohesion or similarity relations between these units. Once
domain-specific concepts from controlled terminologies and the
the document graph has been created, salient nodes within it are
consideration of the structural properties of the documents provide
identified and used to extract the corresponding units for the sum-
additional knowledge that may benefit the summarisation process
and the quality of the summaries. A graph-based summariser is pre-
LexRank is the best-known example of a graph-based
sented that uses the UMLS to identify concepts and the semantic
method for multi-document summarisation. It assumes a fully
relations between them to construct a rich semantic representation
connected and undirected graph for the set of documents to be
of the document to be summarised. Three strategies for sentence
summarised, in which each node corresponds to a sentence rep-
selection are proposed, each of them aiming to construct a different
resented by its TF-IDF vector, and the edges are labelled with
type of summary according to the type of information in the source
the cosine similarity between the sentences. Only the edges that
that is likely to be included in the summary. Moreover, the sum-
connect sentences with a similarity above a predefined threshold
mariser deals with several problems derived from the peculiarities
are drawn in the graph. The sentences represented by the most
of biomedical terminology, such as lexical ambiguity and the use of
highly connected nodes are selected for the summary. A very sim-
acronyms and abbreviations.
ilar method, TextRank, is proposed by Mihalcea and Tarau
The paper is organised as follows. Section the back-
TextRank differs from LexRank in three main aspects: first, it is
ground and related work on text summarisation and UMLS concept
intended for single-document summarisation; second, the similar-
annotation. Section the method of summarisation and
ity between sentences (i.e., the weight of the edges in the document
the evaluation methodology. Section the evaluation results
graph) is measured as a function of their content overlap; and third,
and compares the system to other popular summarisers. Section
the PageRank algorithm used to rank the nodes in the doc-
these results. The final section provides concluding
ument graph. Most recently, Litvak and Last a novel
remarks and describes future lines of work.
approach that uses a graph-based syntactic representation of tex-
tual documents for keyword extraction, which can be used as a
first step in single-document summarisation. They represent the
document as a directed graph, where the nodes represent single
words found in the text, and the edges (not labelled) represent
2.1. Previous work in summarisation
precedence relations between words. A hyperlink-induced topic
search algorithm then run on the document graph under
Text summarisation is the process of automatically creating
the assumption that the top-ranked nodes should represent the
a compacted version of a given text. Content reduction can be
document keywords.
addressed by selection and/or by generalisation of what is impor-
Although these approaches are promising, they exhibit impor-
tant in the source definition suggests that two generic
tant deficiencies that are consequences of not capturing the
groups of summarisation methods exist: those that generate
semantic relationships between terms (synonymy, hypernymy,
extracts and those that generate abstracts. Extractive summarisa-
homonymy and co-occurrence relations). The following sentences
tion produces summaries by selecting salient sentences from the
illustrate such problems:
original document, and therefore the summaries are essentially
composed of material that is explicit in the source. In contrast,
1. Cerebrovascular diseases during pregnancy result from any of
abstractive summarisation constructs summaries in which the
three major mechanisms: arterial infarction, haemorrhage or
information from the source has been paraphrased. Although
venous thrombosis.
human summaries are typically abstracts, most existing systems
2. Brain vascular disorders during gestation result from any of three
produce extracts largely because extractive summarisation has
major mechanisms: arterial infarction, haemorrhage or venous
been demonstrated to report better results than abstractive sum-
marisation superiority is due to the difficulties entailed
by the abstraction process, which usually involves identifying the
Because the two sentences present different terms, the
most prevalent concepts in the source, the appropriate semantic
approaches above are unable to make use of the fact that they have
representation of them and the rewriting of the summary through
exactly the same meaning. This problem may be solved by deal-
natural language generation techniques.
ing with concepts instead of terms and with semantic relations
Extractive methods typically construct summaries based on a
instead of lexical or syntactical ones. Consequently, some recent
superficial analysis of the source. Early summarisation systems
approaches have adapted existing methods to represent the docu-
were based on what Mani called the Edmundsonian paradigm
ment at a conceptual level.
In this paradigm, sentences are ranked using simple heuristic fea-
For example, in the biomedical domain, Reeve et al.
tures, such as the position of the sentences in the document
the lexical chaining approach use UMLS concepts rather
the frequency of their terms the presence of certain cue
than terms and apply it to single-document summarisation. They
words and indicative phrases the word overlap between the
automatically identify UMLS concepts in the source and chain
sentences and the document title and headings features
them so that each chain contains a list of concepts belonging
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
to the same UMLS semantic type. The concept chains are then
knowledge about the article layout can be exploited to improve the
scored by multiplying the frequency of the most frequent concept
summaries that are generated automatically.
in the chain by the number of distinct concepts in it, and these
Second, the peculiarities of the terminology make it diffi-
scores are used to identify the strongest concept chains. Finally,
cult to automatically process biomedical information The
the sentences are scored based on the number of concepts that
first challenge is the problem of synonyms (the use of different
they contain from strong chains. Yoo and colleagues the
terms to designate the same concept) and homonyms (the use of
Medical Subject Headings (MeSH) represent a corpus of
words/phrases with multiple meanings). For instance, the syn-
documents as a graph, where the nodes are the MeSH descriptors
tagms coronary failure and heart attack stand for the same concept,
found in the corpus, and the edges represent hypernymy and co-
while the term anaesthesia may refer to either the loss of sensation
occurrence relations between them. The concepts are clustered to
or the procedure for pain relief. Another handicap to automatic
identify groups of documents dealing with the same topic using
concept recognition is the presence of neologisms, which are newly
a degree-ranking method. Each document cluster is then used
coined words that are not likely to be found in a dictionary (e.g.,
to produce a single summary. For this purpose, they construct a
the term coumadinise for the administration of coumadin). Finally,
text semantic interaction network that represents the set of docu-
elisions and abbreviations complicate the automatic processing of
ments to be summarised, using only the semantic relations found
medical texts. Elision is the omission of words or sounds in a word
in the document cluster. BioSquash a question-oriented
or phrase. An example of elision is white count, understood by physi-
extractive system for biomedical multi-document summarisation.
cians as the count of white blood cells. An abbreviation is a shortened
It constructs a graph that contains concepts of three types: onto-
form of a word or phrase, for example, the use of OCP to refer to oral
logical concepts (general ones from WordNet specific
ones from the UMLS), named entities and noun phrases. The edges
of this graph represent semantic relationships between concepts,
2.3. The use of the UMLS for automatic concept annotation
but nothing is said about the specific relationships used. A more
complex work is presented in Fiszman et al. They propose
The UMLS a collection of controlled vocabularies
an abstractive approach that relies on the semantic predications
related to biomedicine that contains a wide range of information
provided by SemRep interpret biomedical text and on a
that can be used for natural language processing (NLP). It consists of
transformation step using lexical and semantic information from
three main components: the Specialist Lexicon, the Metathesaurus
the UMLS to produce abstracts from biomedical scientific articles.
and the Semantic Network.
However, these abstracts are presented in a graphical format, and
The UMLS Specialist Lexicon a database of lexicographic
the production of textual summaries using language generation
information conceived especially for NLP systems to address the
techniques has been relegated to future work.
high degree of variability in natural language words. It is intended
A recent technique that has proved to be useful for summari-
to be a general English lexicon but also includes many biomedical
sation is sentence simplification. Although it is beyond the scope
terms. The lexicon entry for each word records syntactic, morpho-
of this work, it is expected to provide future improvement of the
logical and orthographic information. The UMLS Metathesaurus
methods. Sentence simplification or compression can be consid-
comprises a collection of biomedical and health related concepts
ered as a means of creating more space within which to capture
derived from more than 100 different vocabulary sources, their var-
important content by producing a simpler and shorter version
ious names and the relationships among them. The UMLS Semantic
of a sentence while retaining the relevant information
Network of a set of categories (or semantic types) that
tence simplification approaches have been little explored in the
provides a consistent categorisation of the concepts in the Metathe-
biomedical domain, mainly due to the complexity of the sentences.
saurus, along with a set of relationships (or semantic relations) that
Recently, the BioSimplify system the utility of sentence
exist between the semantic types.
simplification to improve the output of parsers in biomedical liter-
Using the UMLS for NLP tasks instead of another biomedi-
ature, while Jonnalagadda and Gonzalez the impact
cal knowledge source (e.g., the Systematized Nomenclature of
of sentence simplification on the extraction of protein–protein
Medicine-Clinical Terms (SNOMED-CT) MeSH offers
interactions from biomedical articles. Lin and Wilbur
two main advantages: (1) a broader coverage, as it is a compendium
that sentence compression of biomedical article titles facilitates
of vocabularies including SNOMED-CT and MeSH and (2) support by
user decisions regarding whether an article is worth examining
a number of resources that aid developers of NLP applications, such
in response to an information need. All of these approaches use a
as lexical tools, concept annotators and word sense disambigua-
series of linguistically motivated trimming rules to remove inessen-
tion algorithms. Moreover, using the UMLS for concept annotation
tial fragments from the parse tree of a sentence.
offers two further advantages: (1) it lists more than 15000 entries
of ambiguous terms (which attenuate the problems of synonymy
and homonymy), and (2) it contains numerous entries for elisions
2.2. Biomedical domain singularities
and abbreviations.
To map biomedical text to concepts in the UMLS Metathesaurus,
Biomedical texts exhibit certain unique attributes that must be
the National Library of Medicine has developed the MetaMap pro-
taken into account in the development of a summarisation sys-
gram employs a knowledge-intensive approach
tem. First, medical information arises in a wide range of document
that uses the Specialist Lexicon in combination with lexical and
types EHR, scientific articles, semi-structured databases, X-ray
syntactic analysis to identify noun phrases in text.
images and even videos. Each document type presents very distinct
Matches between noun phrases and Metathesaurus concepts
characteristics that should be considered in the summarisation pro-
are computed by generating lexical variations and allowing par-
cess. We focus on scientific articles, which are mainly composed of
tial matches between the phrase and the concept. The possible
text but usually contain tables and images that may contain impor-
UMLS concepts are assigned scores based on the closeness of the
tant information that should appear in the summary. Biomedical
match between the input noun phrase and the target concept. The
papers often present the IMRaD structure (Introduction, Method,
highest scoring concepts and their semantic types are returned.
Results and Discussion), but sometimes also present additional sec-
this mapping for the syntagm heart attack trial. The first
tions such as abbreviations, limitations of the study and competing
section in the MetaMap response (meta candidates) shows the can-
interests. In most cases, depending on the summarisation task, this
didate concepts, whereas the second section (meta mapping) shows
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
Fig. 1. An example of MetaMap mapping for the syntagm heart attack trial. Each candidate mapping is given a score and is represented by its name in the Metathesaurus (in
parentheses) and its semantic type in the Semantic Network (in brackets).
the highest scoring candidates. Each candidate is represented by
similar clinical cases based on mapping the text in EHR onto UMLS
its MetaMap score, its concept name in the Metathesaurus and its
concepts and representing the patient records as a set of semantic
semantic type in the Semantic Network.
graphs. Each of these graphs corresponds to a different category of
The UMLS and MetaMap have been used in a number of biomed-
information (e.g., diseases, symptoms and signs or medicaments).
ical NLP applications, including machine translation
These categories are automatically derived from the UMLS seman-
answering information retrieval et al.
tic types to which the concepts in the records belong.
instance, modify a simple statistical machine translation system
to use information from UMLS concepts and semantic types, thus
3. Methods
achieving a significant improvement in translation performance.
Overby et al. that both the UMLS Metathesaurus and
3.1. Summarisation method
the MetaMap program are useful for extracting answers to trans-
lational research questions from biomedical text in the field of
In this section, the concept graph-based summariser is pre-
genomic medicine. Aronson and Rindflesch MetaMap to
sented. The method accomplishes the task of identifying the N
expand queries with UMLS Metathesaurus concepts. The authors
most relevant sentences in a document through seven steps: (1)
conclude that query expansion based on the UMLS improves
document preprocessing, (2) concept recognition, (3) sentence
retrieval performance and compares favourably with retrieval
representation, (4) document representation, (5) concept cluster-
feedback. Plaza and Díaz a method for the retrieval of
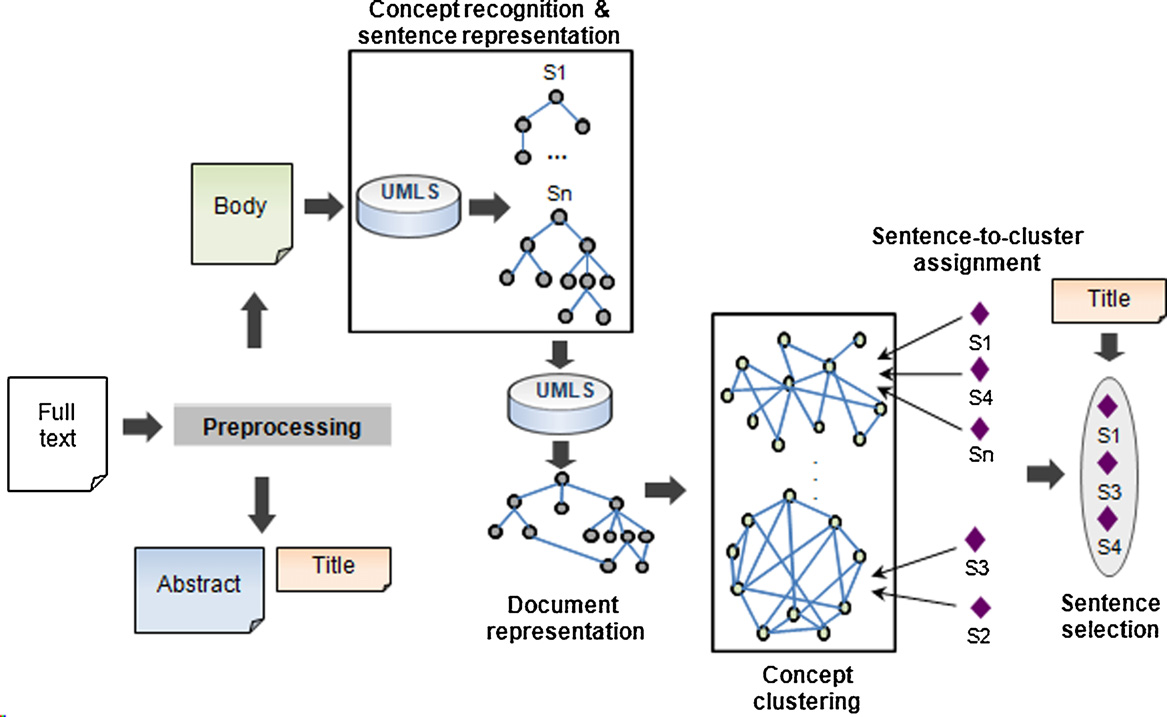
ing, (6) sentence-to-cluster assignment and (7) sentence selection.
Fig. 2. Summariser architecture. The figure shows the seven steps involved in the algorithm: (1) preprocessing, (2) concept recognition, (3) sentence representation, (4)
document representation, (5) concept clustering, (6) sentence-to-cluster assignment and (7) sentence selection.
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
Each step is discussed in detail in the following subsections.
the purpose of summarisation; the document sections that have to
the architecture of the summarisation method. More-
be ignored; the XML tags (if any) that enclose the title, abstract,
over, to clarify how the algorithm works, a complete document
body and abbreviations sections; the format used to specify the
example from the BioMed Central corpus cvm-2-6-
abbreviations and their expansions; or the stop list to be used.
254.xml) is elaborated throughout the summarisation process. It is
worth mentioning that, although our interest here is to summarise
3.1.2. Concept recognition
biomedical literature, the summarisation method is generic and
The next stage is to map the text in the document to concepts
may be adapted to work with different types of documents (see
from the UMLS Metathesaurus and semantic types from the UMLS
and examples of preliminary applications to summarising
Semantic Network.
news items and tourism-related web sites, respectively).
The MetaMap program is run over the text in the body section
of the document. In particular, the 2009 version of MetaMap is
3.1.1. Document preprocessing
employed, and the 2009AA UMLS release is used as the knowledge
A preliminary step is undertaken to prepare the document for
base. It is important to note that, in the presence of lexical ambi-
the subsequent steps. This preprocessing involves the following
guity, MetaMap frequently fails to identify a unique mapping for a
given phrase failure occurs, for instance, for the phrase
Tissues are often cold, where MetaMap returns three candidate con-
• First, sections of the document that are considered irrelevant
cepts with equal scores for cold (cold sensation, common cold and
for inclusion in the summary are removed: competing interests,
cold temperature). To select the correct mapping for the context
acknowledgments, references and section headings.
in which the phrase appears, MetaMap is invoked using the word
• Second, if the document includes an abbreviations section, the
sense disambiguation option (-y flag). This flag implements the
abbreviations and their expansions are extracted from it. This
Journal Descriptor Indexing (JDI) methodology described in
information is then used to replace these shortened forms in the
This algorithm is based on semantic type indexing, which resolves
document body. For example, if the abbreviations section defines
Metathesaurus ambiguity by choosing a concept with the most
embryonic submandibular as the expansion of SMG for a particu-
likely semantic type for a given context. Using the–y flag forces
lar document, and if that document contains the phrase Survivin
MetaMap to choose a single mapping if there is more than one can-
may be a key mediator of SMG epithelial cell survival, then that
didate concept for a given phrase. However, when the candidate
phrase would become Survivin may be a key mediator of embryonic
concepts share the same semantic type, the JDI algorithm may fail
submandibular epithelial cell survival.
to return a single mapping. In this case, the first mapping returned
• Third, to expand the acronyms and abbreviations not defined in
by MetaMap is selected.
the abbreviations section, the software for abbreviation definition
Concepts from very generic UMLS semantic types are discarded
recognition presented in used. This software is publicly
because they have been found to be excessively broad. These
available allows for the identification of abbreviations
semantic types are quantitative concept, qualitative concept, tempo-
and their expansions in biomedical texts with an average preci-
ral concept, functional concept, idea or concept, intellectual product,
sion of 95%. Abbreviations are then replaced by their expansions
mental process, spatial concept and language. These types were
in the document body.
empirically determined by evaluating the summaries generated
• Fourth, the title, abstract and body sections are extracted.
using UMLS concepts from different combinations of semantic
• Fifth, using a stop list from Medline generic terms (e.g.,
prepositions and pronouns) in the body and title sections are
the UMLS concepts identified for the sentence
removed because they are not useful in discriminating between
S1: The goal of the trial was to assess cardiovascular mortality
relevant and irrelevant sentences.
and morbidity for stroke, coronary heart disease and congestive
• Finally, the text in the body section is split into sentences using
heart failure, as an evidence-based guide for clinicians who treat
the tokenizer, part of speech tagger and sentence splitter modules
of the GATE architecture for text engineering
3.1.3. Sentence representation
The preprocessing step can easily be configured to deal with doc-
For each sentence in the document, the UMLS concepts returned
uments of different structures and with unstructured documents. A
by MetaMap are retrieved from the UMLS Metathesaurus along
config.xml file allows users to specify, for instance, if the document
with their complete hierarchy of hypernyms (is a relations). All the
is not structured and thus the entire text should be considered for
hierarchies for each sentence are merged, creating a sentence graph
MetaMap mapping for the sentence The goal of the trial was to assess cardiovascular mortality and morbidity for stroke, coronary heart disease and congestive heart failure,
as an evidence-based guide for clinicians who treat hypertension. Ignored concepts of generic semantic types appear crossed out.
Goals 1000
Clinical trials
vasc ular s
yste m 694
Mortality vital statistics 86
Morbidity – dise
Cerebrovascular accident
Coronary heart disease
Congestive heart failure 10
Evidence of
tion al co ncept
Clinicians 1000
Treatment intent
tion al co ncept
Hypertensive disease
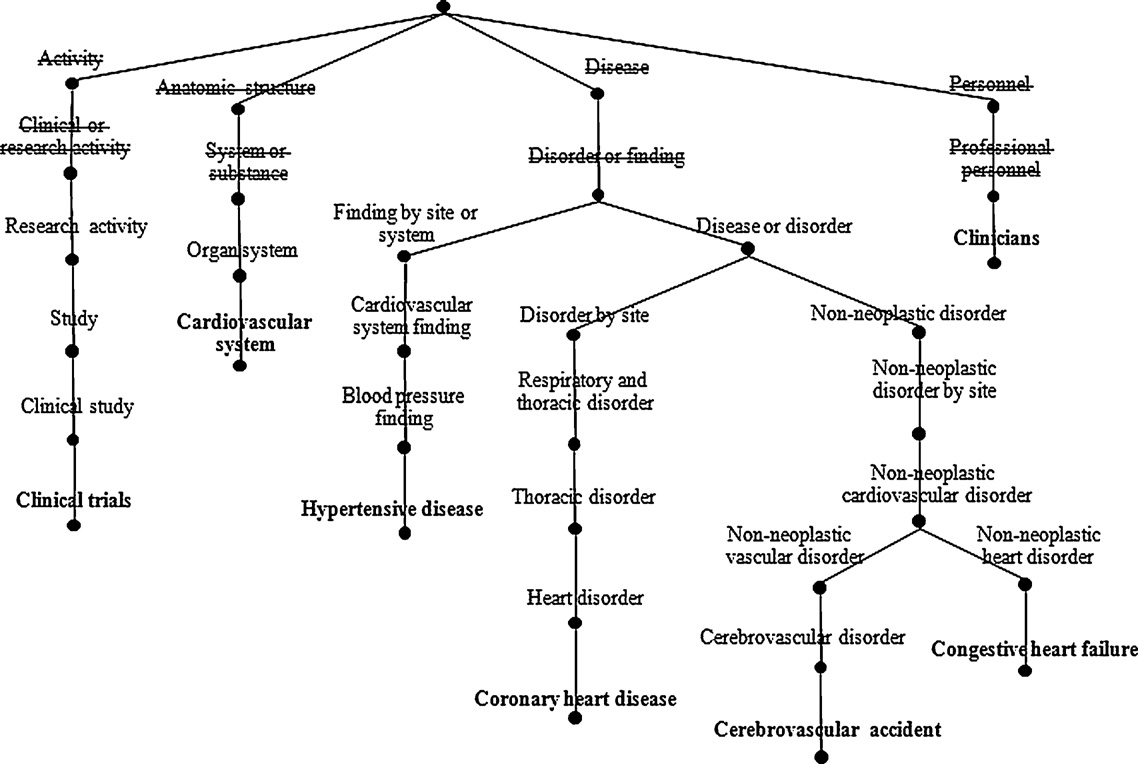
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
Fig. 3. An example of a sentence graph for the sentence The goal of the trial was to assess cardiovascular mortality and morbidity for stroke, coronary heart disease and congestive
heart failure, as an evidence-based guide for clinicians who treat hypertension. Very general concepts that are ignored appear crossed out. Final concepts are shown in bold type.
where the edges (temporally unlabelled) represent semantic rela-
leaf vertices is always 1.0. Thus, the weighting function attaches
tions, and only a single vertex is created for each distinct concept in
greater importance to specific concepts than to general ones.
the text. Finally, the two upper levels of this hierarchy are removed,
again because they represent very general concepts.
i) if e represents an is a relation
weight(vi, vj) = � where
the graph for the example sentence used in the previous section.
� = 1.0 otherwise
This principle is shown in the is a link between the
3.1.4. Document representation
concepts cardiovascular drug and alpha-adrenergic blocking agent is
Next, all the sentence graphs are merged into a single document
assigned the weight 1/2 because cardiovascular drug is ranked first
graph. This graph can be extended using more specific relation-
in its hierarchy and alpha-adrenergic blocking agent is ranked second
ships between nodes to obtain a more complete representation of
in the same hierarchy. The related to link between the leaf concepts
the document. In particular, in this work, the following sets of rela-
doxazosin and chlorthalidone is assigned the weight 1.0.
tions are tested: (1) no relation (apart from hypernymy), (2) the
associated with relation between semantic types from the UMLS
Semantic Network, (3) the related to relation between concepts
3.1.5. Concept clustering
from the UMLS Metathesaurus and (4) both the associated with and
The following step groups the UMLS concepts in the document
related to relations. To expand the document graph, only relations
graph using a degree-based clustering algorithm similar to the one
that link leaf vertices are added.
proposed in aim is to construct sets or clusters of concepts
an example of a document graph for a simplified
that are closely related in meaning, under the assumption that each
document composed of two sentences extracted from the docu-
cluster represents a different subtheme in the document and that
ment cvm-2-6-254.xml from the BioMed Central corpus:
the most central concepts in the clusters (the centroids) give the
necessary and sufficient information related to each subtheme.
The working hypothesis is that the document graph is an
S1. The goal of the trial was to assess cardiovascular mortality
instance of a scale-free network A scale-free network is a
and morbidity for stroke, coronary heart disease and conges-
complex network whose degree distribution follows a power law
tive heart failure, as an evidence-based guide for clinicians who
P(k) ∼ k−� , where k stands for the number of links originating from
treat hypertension
a given node. The most notable property in this type of networks
S2. While event rates for fatal cardiovascular disease were similar,
is that some nodes have a degree that considerably exceeds the
there was a disturbing tendency for stroke to occur more often
average. These highest-degree nodes are often called hubs.
in the doxazosin group, than in the group taking chlorthalidone.
The salience of each vertex in the graph is then computed. Fol-
lowing salience of a vertex, vi, is defined as the sum of the
Next, each edge of the document graph is assigned a weight in
weights of the edges, e that are connected to it, as shown in Eq.
[0,1], as shown in Eq. weight of an edge, e, representing an
is a relation between two vertices, vi and vj (where vi is a parent of
vj), is calculated as the ratio of the depth of vi to the depth of vj from
salience(v =
the root of their hierarchy. The weight of an edge representing any
other relation (i.e., associated with or related to) between a pair of
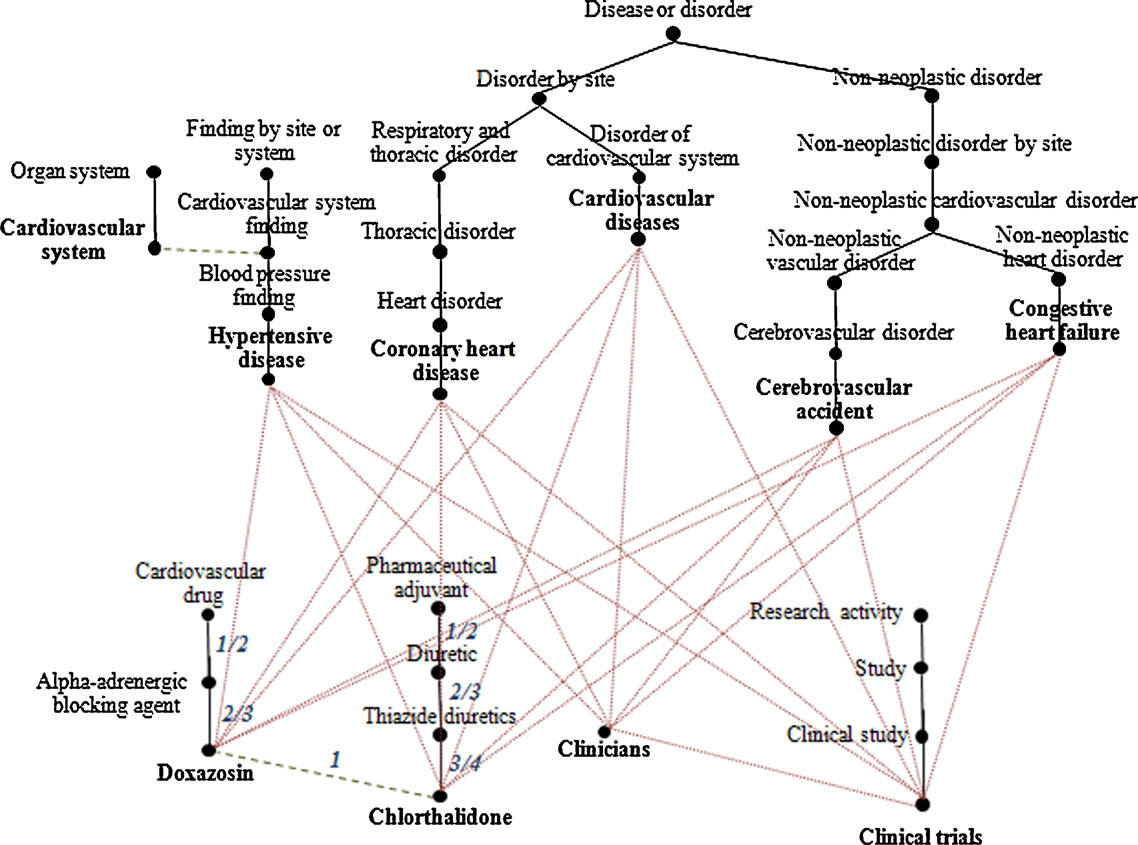
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
Fig. 4. An example of a simplified document graph from sentences S1 and S2. Continuous lines represent hypernymy relations; dashed lines represent related to relations;
and dotted lines represent associated with relations. The edges of a portion of this graph have been labelled with their weights.
The n vertices with the highest salience (the hub vertices) rep-
the final clusters consist of the HVSs resulting from the clustering
resent the most connected nodes in the graph, taking into account
algorithm plus the non-HVS vertices that are later attached to them.
both the number and the weight of the edges. The clustering algo-
rithm starts grouping the hub vertices into hub vertex sets (HVSs)
HVSs can be interpreted as sets of concepts strongly
connectivity(v, C =
related in meaning and will represent the centroids of the clusters.
To construct the HVSs, the clustering algorithm first identifies the
pairs of hub vertices that are most closely connected and merges
them into a single HVS. Then, for each pair of HVSs, the algorithm
checks whether the internal connectivity of the vertices they con-
two fragments of two clusters from the document
tain is lower than the connectivity between them. If so, the HVSs
example. The purpose of this figure is to give readers an idea of the
are merged. This decision is encouraged by the assumption that
appearance of the clusters generated by the algorithm. The entire
the clustering should show maximum intra-HVS connectivity but
clusters present, respectively, 182 and 27 concepts. The cluster-
minimum inter-HVS connectivity. Intra-connectivity for a HVS is
ing method produces four clusters for the full document. It may
calculated as the sum of the weights of all edges connecting two
be observed that cluster A groups concepts related to diseases,
vertices within the HVS, as shown in Eq. for
syndromes and findings, as well as concepts regarding chemical
two HVSs is computed as the sum of the weights of all edges con-
and pharmacological substances, while cluster B collects concepts
necting two vertices, each vertex belonging to one of the HVSs, as
related to population and professional groups.
3.1.6. Sentence-to-cluster assignment
j ∃v,w ∈ HVS
Once the concept clusters have been created, the aim of this
step is to compute the semantic similarity between each sentence
inter-connectivity(HVSi, HVSj) =
graph and each cluster. As the two representations are quite dif-
k ∃v ∈ HVS
ferent in size, traditional graph similarity metrics (e.g., the edit
j ∧ek connect(v,w)
distance are not appropriate. Instead, the similarity between
Once the centroids of the clusters have been determined, the
a sentence graph and a cluster is computed using a non-democratic
remaining vertices (i.e., those not included in the HVSs) are itera-
voting mechanism, so that each vertex, v within a sentence graph,
tively assigned to the cluster to which they are more connected. The
Sj, assigns a vote to a cluster, Ci, if the vertex belongs to the HVS of
connectivity between a vertex, v, and a cluster, Ci, is computed as
that cluster; half a vote if the vertex belongs to the cluster but not
the sum of the weights of the edges that connect the target vertex
to its HVS; and no votes otherwise. The similarity between the sen-
to the other vertices in the cluster, as shown in Eq.
tence graph and the cluster is then calculated as the sum of the
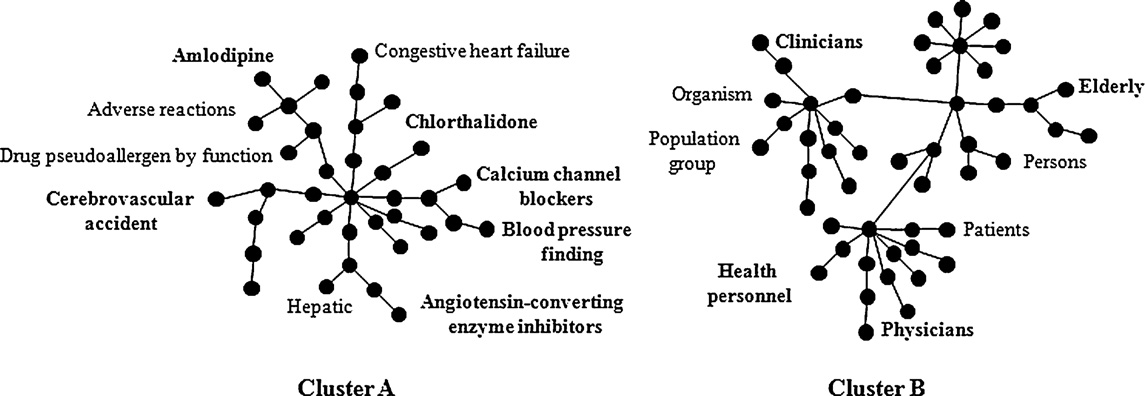
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
Fig. 5. An example of two fragments of two out of the four clusters extracted from the document example. The hub vertices are shown in bold type. The entire clusters
present, respectively, 182 and 27 concepts.
votes assigned to the cluster by all vertices in the sentence graph,
�semanticsimilarity(C S
semantic similarity (S =
vk /∈ Ci ⇒ wk,i,j = 0
semantic similarity(Ci, Sj) =
vk ∈ HVS(Ci) ⇒ wk,i,j = 1.0 (6)
Two additional features, apart from semantic similarity, have
vk /∈ HVS(Ci) ⇒ wk,i,j = 0.5
been tested in computing the relevance of the sentences: sen-
vk vk ∈ S j
tence position and similarity to the title. Despite their simplicity,
these features are still commonly used in the most recent works on
Next, for each cluster, the sentences are ranked in decreasing
extractive summarisation
order of semantic similarity. It should be noted that a sentence
may assign votes to several clusters (i.e., it may contain information
about different themes).
Sentence position: The position of the sentences in the document
To illustrate this process, consider the sentence S1 presented in
has been traditionally considered an important factor in finding
Section its sentence graph shown in seman-
the sentences that are most related to the topic of the document
tic similarity between this sentence graph and cluster A in
close to the beginning and the end of the
equal to 2.5 because the concepts blood pressure finding and cardio-
document are expected to deal with the main theme of the doc-
vascular accident belong to the HVS of the cluster and each receive
ument, and therefore more weight is assigned to them. In this
one vote, while the concept congestive heart failure belongs to the
work, a position score ∈ [0,1] is calculated for each sentence as
cluster but not to its HVS, thus receiving half a vote. The remaining
shown in Eq. M represents the number of sentences in
concepts in the sentence graph do not belong to the cluster, and
the document and mj represents the position of the sentence, Sj,
thus they do not receive any vote.
within the document.
3.1.7. Sentence selection
At this point in, it is important to remember that extractive
summarisation works by choosing salient sentences in the original
document. In this work, sentence selection is assessed based on the
• Similarity to the title: The title given to a document by its author
similarity between sentences and clusters, as defined in Eq.
is intended to represent the most significant information in the
number of sentences to be selected (N) depends on the desired sum-
document, and thus it is frequently used to quantify the relevance
mary compression. Three different heuristics for sentence selection
of a sentence this work, the similarity of a sentence to the
have been investigated:
title is computed as the proportion of UMLS concepts in common
between the sentence and the title, as shown in Eq.
• Heuristic 1: Under the hypothesis that the cluster with the most
concepts represents the main theme or topic in the document, the
{concepts S ∩ {concepts title}
top ranked N sentences from this cluster are selected. The aim of
{concepts S ∪ {concepts title}
this heuristic is to include in the summary only the information
related to the main topic of the document.
The final selection of the sentences for the summary is based on
• Heuristic 2: All clusters contribute to the summary in proportion
the weighted sum of these feature values, as stated in Eq.
to their sizes. Therefore, for each cluster, the top ranked n
values for the parameters ,
must be determined empiri-
tences are selected, where n
i is proportional to the size of the
cluster. The aim of this heuristic is to include in the summary
score(Sj) = � × semantic similarity(Sj) + � × position(Sj) + � × title(Sj)
information about all the topics covered in the source.
• Heuristic 3: Halfway between the two heuristics above, this
It should be noted that the sentences in the summary are placed
heuristic modifies Eq. compute a single score for each sen-
in the same order in which they appear in the source. Also, because
tence as the sum of the votes assigned to each cluster, adjusted
a sentence may assign votes to several clusters or themes, heuristic
by their sizes, as shown in Eq. Then, the N highest scoring
2 might include repeated sentences in the summary. To avoid this
sentences are selected. The aim of this heuristic is to select most
repetition, the system avoids adding to the summary any sentence
of the sentences from the main topic of the document but also
that is already part of it. Finally, the tables and figures in the source
to include other secondary information that might be relevant to
that are referred to in any sentence belonging to the summary are
also included in it.
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
3.2. Evaluation method
matching instead of semantic matching. Therefore, peer summaries
that are worded differently but carry the same semantic informa-
The purpose of the experiment is to evaluate the adequacy of
tion may be assigned different ROUGE scores. In contrast, the main
semantic graphs for extractive summarisation and to compare the
advantages of ROUGE are its simplicity and its high correlation with
method with other well-known research and commercial sum-
the human judges gathered from previous DUC conferences
marisers. The evaluation is accomplished in two phases: (1) a
preliminary experiment to find the best values for the different
3.2.2. Evaluation corpus
parameters involved in the algorithm and (2) a large-scale eval-
To the authors' knowledge, no corpus of model summaries exists
uation following the guidelines in the 2004 and 2005 Document
for biomedical documents. However, most scientific papers include
Understanding Conferences (DUC
an abstract (i.e., the author's summary), which can be used as a
model summary for evaluation.
3.2.1. Evaluation metrics: ROUGE
In this work, a collection of 300 biomedical scientific articles
Although the evaluation of automatically generated summaries
randomly selected from the BioMed Central full-text corpus for
is a critical issue, there is still a controversy as to what the evalu-
text mining research used for evaluation. This corpus con-
ation criteria should be, mainly due to the subjectivity in deciding
tains approximately 85,000 papers of peer-reviewed biomedical
whether or not a summary is of good quality
research, available in XML structured format, which allowed us to
evaluation methods can be classified into two broad categories,
easily identify the title, abstract, figures, tables, captions, citation
intrinsic and extrinsic, depending on whether the outcome is eval-
references, abbreviations, competing interests and bibliography
uated independently of the purpose that the summary is intended
sections. As stated in document sample size is large enough
to serve. Because the method proposed here is not designed for
to allow significant evaluation results. The abstracts for the papers
any specific task, the interest is on intrinsic evaluation. Intrinsic
were used as reference summaries.
evaluation techniques test the summarisation itself, primarily by
measuring two desirable properties of the summary: coherence
3.2.3. Algorithm parametrisation
and informativeness. Summary coherence refers to text readability
A preliminary experiment was performed to determine, accord-
and cohesion, while informativeness aims at measuring how much
ing to ROUGE scores, the optimal values for the parameters involved
information from the source is preserved in the summary
in the algorithm. This preliminary work addressed the following
The automatically generated summaries may be evaluated man-
research questions:
ually, but this process is both very costly and time-consuming
because it requires human judges to read not only the summaries
1. Which set of semantic relations should be used to construct the
but also the source documents. Besides, to objectively judge a sum-
document graph? (Section
mary has been proven difficult, as humans often disagree on what
2. What percentage of vertices should be considered as hub vertices
exactly makes a summary of good quality a consequence,
by the clustering method? (Section
the research community has lately focused on the search for met-
3. Does the use of traditional criteria (i.e., the position of the sen-
rics to automatically evaluate the quality of a summary. Several
tences and their similarity with the title) improve the quality of
metrics have been proposed to automatically evaluate informative-
the summaries? (Section
ness However, to the best of our knowledge, research in
4. Which of the three heuristics for sentence selection produces the
automatic evaluation of coherence is still very preliminary
best summaries? (Section
In this work, the recall-oriented understudy for gisting evalua-
tion (ROUGE) package used to evaluate the informativeness
A separate development set was used for this parametrisation.
of the automatic summaries. ROUGE is a commonly used evalu-
This set consisted of 50 documents randomly selected from the
ation method that compares an automatic summary (called peer)
BioMed Central corpus. Again, the abstracts of the papers were used
with one or more human-made summaries (called models or ref-
as model summaries.
erence summaries) and uses the proportion of n-grams in common
between the peer and model summaries to estimate the content
3.2.4. Comparison with other summarisers
that is shared between them. The more content shared between
Our approach was compared with three summarisers: two
the peer and model summaries, the better the peer summary is
research prototypes (SUMMA and LexRank) and a commercial appli-
assumed to be. The ROUGE metrics produce a value in [0,1], where
cation (Microsoft Autosummarize). SUMMA a single- and
higher values are preferred, as they indicate a greater content
multi-document summariser that provides several customisable
overlap between the peer and model summaries. The following
statistical and similarity-based features to score the sentences for
ROUGE metrics are used in this work: ROUGE-1 (R-1), ROUGE-2
extraction. It is one of the most popular research summarisers
(R-2), ROUGE-W-1.2 (R-W) and ROUGE-SU4 (R-SU4). R-N eval-
and is publicly available. The features used for this evaluation
uates n-gram occurrence, where N stands for the length of the
include the position of the sentences within the document and
n-gram. R-W-1.2 computes the union of the longest common sub-
within the paragraph, their overlap with the title and abstract sec-
sequences between the peer and the model summary sentences,
tions, their similarity to the first sentence, and the frequency of
taking into account consecutive matches. Finally, R-SU4 evaluates
their terms. Comparison with LexRank allow us to evalu-
"skip bigrams", that is, pairs of words having intervening word gaps
ate whether semantic information provides benefits over merely
no larger than four words.
lexical information in graph-based summarisation approaches.
It should be noted, however, that ROUGE metrics do not account
Microsoft Autosummarize a feature of the Microsoft Word
for text coherence, but merely assess the content of the summaries.
software and is based on a word frequency algorithm. In spite
An important drawback of ROUGE metrics is that they use lexical
of its simplicity, word frequency is a well-accepted heuristic for
summarisation. In addition, two baseline summarisers have been
implemented. The first, lead baseline, generates summaries by
selecting the first N sentences from each document. The second,
The DUC conferences (now the Text Analysis Conferences, TAC) are an initiative
random baseline, randomly selects N sentences from the document.
of the National Institute of Standards and Technology aimed at developing power-
ful summarisation systems and evaluation methods and at enabling researchers to
All automatic summaries were generated by selecting sentences
participate in large-scale experiments.
until the summary is 30% of the original document size. This choice
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
ROUGE scores for different combinations of semantic relations and percentages of hub vertices. The best results for each heuristic and set of relations are shown in italics,
while the scores in bold indicate the best results for each heuristic.
Hypernymy & associated with
Hypernymy & related to
Hypernymy & associated with & related to
of summary size is based on the well-accepted heuristic that a sum-
number of relations (i.e., with the connectivity of the document
mary should be between 15% and 35% of the size of the source
text the length of the authors' abstracts is, on aver-
The aim of the second group of experiments was to learn if the
age, 17% of the length of documents, a larger size was preferred
use of the positional and similarity to the title criteria to select sen-
because the documents used for the experiments (i.e., scientific
tences for the summaries helps to improve the content quality of
articles) are rich in information. The text in the tables and figures
these summaries (see Section For these experiments, the
that are included in the summary was not taken into account when
percentage of hub vertices was set to 5% for heuristics 1 and 3 and
computing the summary size.
to 10% for the second heuristic. All semantic relations were used
A Wilcoxon signed-rank test with a 95% confidence interval was
to construct the document graph. The ROUGE scores for these tests
used to test the statistical significance of the results.
are presented in with the values for the parameters
�, � and � that define the weight of each criterion in the linear func-
4. Experimental results
tion presented in Eq. determine the values of �, � and �,
all possible combinations that arise from varying � from 0.5 to 1.0
4.1. Parametrisation results
and varying � and � from 0.1 to 0.5, at −0.1 intervals, were tested.
However, for the sake of brevity, only the combinations that pro-
To answer the questions raised in Section groups of
duced the best ROUGE scores are presented. It is worth mentioning
experiments were performed. The first group was conducted to find
that the experiments showed that � values below 0.7 produce very
the best combination of semantic relations for building the docu-
poor results.
ment graph (Section and the best percentage of hub vertices
It may be seen from according to the ROUGE scores,
for the clustering method (Section Note that both parame-
the use of the positional and similarity to the title criteria does not
ters must be evaluated together because the relations influence the
benefit heuristic 3. In contrast, the results obtained by the second
connectivity of the document graph and thus the optimum percent-
heuristic improve slightly when both criteria are used. Regarding
age of hub vertices. The results of these experiments are presented
heuristic 1, while the positional criterion does not improve the
in For legibility reasons, only R-2 and R-SU4 scores are
scores for any of the ROUGE metrics, the effect of the similarity to the
title criterion is not clear because the use of that criterion increases
It may be observed from the three heuristics behave
R-2 but decreases R-SU4. Again, heuristics 1 and 3 behave better
better when all three semantic relations (i.e., hypernymy, associated
than heuristic 2. shows that the similarity to the title
with and related to) are used to build the document graph. How-
criterion contributes more to the quality of the summaries than
ever, the best percentage of hub vertices depends on the heuristic.
the positional one for all the heuristics.
Heuristics 1 and 3 perform better when 5% of the concepts in the
Therefore, it may be concluded from that the
document graph are used as hub vertices, while heuristic 2 regis-
best configuration for heuristic 1 involves using the three seman-
ters the best outcome when the percentage of hub vertices is set to
tic relations with 5% of hub vertices and no information about the
10%. Heuristics 1 and 3 achieve slightly better results than heuristic
position of the sentences in the document. However, no definitive
2, the best result being reported by the third heuristic. It may be
conclusions can be drawn about the use of the similarity to the title
also observed that, on average, the associated with relationship is
criterion, and thus, both configurations will be tested in the final
more effective than the related to relation because the latter links
evaluation. The best configuration for heuristic 2 involves using
together a relatively low number of concepts and thus produces
the three semantic relations with 10% of hub vertices, and both
a quite unconnected document graph. Another interesting result
the sentence position and similarity to the title criteria with weights
is that the optimal percentage of hub vertices increases with the
� = 0.8, � = 0.1 and � = 0.1, respectively. In turn, heuristic 3 works
ROUGE scores for different combinations of sentence selection criteria. The best results for each heuristic are shown in bold type.
Sentence salience
Sentence salience & position
Sentence salience & title similarity
Sentence salience & position & title similarity
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
ROUGE scores for different versions of the summariser, two research systems (LexRank and SUMMA), a commercial application (Microsoft AutoSummarize) and two baselines
(lead and random). The best score for each metric is shown in bold font. Systems are sorted by decreasing R-2 score.
Heuristic 1+ sim. with title
best by using the three semantic relations with 5% of hub vertices
and no other criterion for sentence selection (i.e., � = 1.0, � = 0.0 and
In this section, the experimental results presented in Section
both for the parametrisation and the final evaluation, are discussed.
Various practical applications of the summarisation method are
4.2. Evaluation results
also proposed.
To evaluate the summarisation performance, different types of
summaries have been generated using (1) the three heuristics for
5.1. Algorithm parametrisation
sentence selection with their best configurations concluded in Sec-
tion the SUMMA, LexRank and Microsoft Autosummarize
We first discuss the results of the parametrisation performed to
systems, and (3) the lead and random baselines, as explained in
determine the optimal values for the parameters involved in the
Section ROUGE scores for all summarisers are presented
summariser and provide answers to the questions raised in Section
results were presented in Section
that the three heuristics report higher ROUGE
First, concerning the set of semantic relations that should be
scores than the other summarisers and baselines. The best results
used to build the document graph, that the three
are obtained using heuristic 3. Heuristic 1 (both with and with-
heuristics behave better when all three semantic relations (i.e.,
out using the similarity with the title criterion) and heuristic 3
hypernymy, associated with and related to) are used. However, they
significantly improve all ROUGE metrics compared with SUMMA,
differ in the optimal percentage of hub vertices used to cluster the
LexRank, AutoSummarize and both baselines (Wilcoxon signed-
concepts in the graph (5% for heuristics 1 and 3 versus 10% for
rank test, p < 0.05). The second heuristic significantly improves
heuristic 2). This difference exists because the three heuristics aim
all ROUGE metrics with respect to AutoSummarize and both
to produce different types of summaries. It is worth remembering
baselines, while the improvement with respect to LexRank and
that the aim of heuristic 2 is to generate summaries covering all
SUMMA is only significant for R-1. On the other hand, it
topics presented in the source document, regardless of their rela-
has been found that the first heuristic behaves slightly bet-
tive relevance. Thus, it is not sufficient to consider only the concepts
ter without using the similarity to the title criterion. However,
dealing with the main topic of the document as hub vertices, but
the differences with respect to using it are not statistically
also those dealing with other secondary information.
Second, with respect to the use of traditional criteria for sen-
Concerning comparison between the three heuristics, the per-
tence selection (i.e., the position of the sentences in the document
formance of heuristic 3 is significantly better than that of heuristic
and their similarity to the title), that while heuristic
2 for all ROUGE metrics (R-1: p = 0.0005; R-2: p = 0.045; R-W-1.2:
3 does not benefit from any of these criteria, heuristic 1 produces
p = 0.002; R-SU4: p = 0.0475) and also better than that of heuristic
comparable ROUGE scores regardless of whether or not similarity
1 for R-1 (p = 0.007) and R-SU4 (p = 0.0475). In contrast, the perfor-
with the title criterion is used, but such scores decrease when the
mance of heuristic 1 is significantly better than that of heuristic 2
positional criterion is employed. The results reported by heuristic
for R-1 (p = 0.021) and R-2 (p = 0.045).
2, however, improve when both criteria are used. The reason is that,
Finally, an important research question that immediately arises
because heuristic 2 aims to cover all topics in the document, and
is why the ROUGE scores differ so much across documents. This is
because frequently some of these topics are irrelevant to the sum-
not shown in the tables (as they present the average results) but it
mary, the use of these additional criteria, especially the similarity to
has been observed during the experimentation and can be appre-
the title, biases the selection of sentences toward the information
ciated in This table shows the standard deviation of the
related to the main topic of the document.
different ROUGE scores for the summaries generated by heuristic
We have also found that the similarity to the title criterion con-
tributes more to the quality of the summaries than the positional
criterion for all three heuristics. This result is not surprising because
scientific papers are not (a priori) expected to present the core
information at the beginning and end of the document, as occurs in
other types of documents such as news articles. The first sentences
Standard deviation of ROUGE scores for the summaries generated using heuristic 3.
in scientific papers usually introduce the problem and motivation
Standard deviation
of the study, whereas the last sentences provide conclusions and
future work. However, the most important information is usually
presented in the middle sentences, as part of the method, results
and discussion sections. Therefore, it seems that a more appropriate
positional criterion would be one that attaches greater importance
to sentences belonging to such central sections.
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
Third, regarding the best heuristic for sentence selection,
approach, which also employs domain-specific information (UMLS
that heuristic 3 reports the highest ROUGE
concepts and semantic types) to represent the documents. Reeve
scores. To understand why this heuristic behaves better than the
et al. address the same problem as the one presented here but uses
others, we first examined the authors' abstracts for the 50 docu-
a different evaluation strategy. They use a corpus of 24 oncology
ments in the development set. We found that the information in
papers to generate summaries with a 20% compression rate and
these abstract (i.e., the information considered most important by
compare the automatic summaries with four model summaries:
the authors of the papers) can be classified into three main sections
three models generated by three domain experts, using sentence
or categories: (1) the background of the study, (2) the method or
extraction, and the abstract of the paper. Nonetheless, only the
case presentation and (3) the results and conclusions of the study.
average ROUGE scores for the four models are given. Their best
The method section includes approximately 58% of the informa-
summarisation method reports a R-2 score = 0.12653 and a R-SU4
tion in the abstract; the results and conclusions section comprises
score = 0.22303. The method proposed here, when run with a 20%
around 25%; and the background section involves less than 17%.
compression rate over the 300 documents in the corpus, obtains
We next analysed the clusters generated by the clustering method
a R-2 score = 0.2568 and a R-SU4 score = 0.2385. Although these
and found that it usually produces a single large cluster and a
results seem to outperform those reported by Reeve et al., it must
variable number of small clusters. The large cluster contains the
be noted that they are not directly comparable due to the use of a
concepts related to the central topic of the document, while the
different corpus and a different evaluation methodology (in partic-
others include concepts related to secondary information. Although
ular, the use of a combination of extracts and abstracts as model
some of the concepts within the large cluster may be found in
all three sections of the abstracts, the majority of the concepts in
this cluster are usually found in the section describing the method.
5.3. Differences across documents
Therefore, it seems clear that any heuristic for sentence selection
that aims to compare well with the authors' abstracts should mainly
The experiment also showed that the ROUGE scores differ con-
include information related to the concepts within this large clus-
siderably across different documents (see To clarify the
ter (i.e., information related to the main topic of the document).
reasons for these differences, the two extreme cases (that is, the
Hence, heuristic 2 is, by definition, at disadvantage compared with
two documents with the highest and lowest ROUGE scores, respec-
heuristics 1 and 3 when the authors' abstracts are used as model
tively, for the summaries generated using the third heuristic) were
summaries. This result does not mean that heuristic 2 is worse than
carefully examined. The best case turned out to be one of the largest
the others, but rather that it aims to generate a different type of
documents in the corpus, while the worst case was one of the
shortest (six pages versus three pages). According to the starting
In spite of this result, the differences among the heuristics are
hypothesis (i.e., the document graph is an instance of scale-free
not as remarkable as expected. A careful analysis of the summaries
network), as the graph grows, the new concepts are likely to be
generated by the three heuristics for the 50 documents in the devel-
linked to other highly connected concepts, and thus the hubs are
opment set suggests that the explanation for this finding is that,
expected to increase their connectivity at a higher rate. Therefore,
given the larger size of the main cluster, the three heuristics extract
the difference in connectivity between the hubs and the remaining
most of their sentences from this cluster, and hence the summaries
vertices is expected to be more marked in large graphs than in mod-
generated share most of the sentences in common. Nevertheless,
estly sized ones. We think that this fact leads to a better separation
the best results are reported by heuristic 3. It has been deter-
of the clusters generated in large graphs than in smaller ones and
mined that this heuristic selects most of the sentences from the
thus to a better delimitation of the topics covered in the document.
most populated cluster, but it also includes some sentences from
A second interesting difference between the documents is in
other clusters. Thus, in addition to the information related to the
their underlying subject matter. The best case is published in the
central topic, this heuristic also includes other secondary or "satel-
BMC Biochemistry journal and concerns the reactions of certain pro-
lite" information that might be relevant to users. In contrast, the
teins over the brain synaptic membranes. In contrast, the worst case
first heuristic fails to present this information, whereas the sec-
is published in the BMC Bioinformatics journal and concerns the use
ond heuristic includes more secondary information but sometimes
of pattern matching for database searching. It has been verified that
omits some of the core information.
the UMLS covers the vocabulary in the first document better than
the vocabulary in the second one, in terms of both concepts and
5.2. Comparison with other summarisers
relations, which leads to a more accurate graph that better reflects
the content of the document.
We next discuss the results of the final evaluation and compare
Finally, in the worst-case document, the use of synonyms is
our system to other summarisers (see Section These results
quite frequent, which does not occur in the best-case document.
were presented in Section
For instance, a concept is referred to in the document body as string
that the ROUGE scores achieved by all variants
searching, but it is always referred to as pattern matching in the
of the concept graph-based method are significantly better than
abstract. Because the ROUGE metrics are based on the number of
those of all other summarisers and baselines. These results seem
word overlaps, the summaries containing synonyms of the terms
to indicate that using domain-specific knowledge improves sum-
in the abstract are unreasonably penalised.
marisation performance compared with traditional word-based
approaches, in terms of the informative content quality of the sum-
5.4. Practical applications
maries generated. The use of concepts instead of terms along with
the semantic relations that exist between them allows the system
In light of the experimental results, we believe that the sum-
to identify the different topics covered in the text more accurately
maries generated by the proposed method may help physicians
and with comparative independence of the vocabulary used to
and biomedical researchers in several ways.
describe them. As a consequence, the information in the sentences
First, automatic summaries may be useful in anticipating the
selected for the summaries is closer to the information in the model
contents of the original documents, so that users may decide which
of the documents to read further. Even with the author's abstract,
A further test has been performed to compare the performance
there are two main reasons for wanting to generate text summaries
of heuristic 3 with that of the Reeve et al.
from a full-text the abstract may be missing relevant content
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
from the full-text, and (2) there is not a single ideal summary, but
concepts not covered by UMLS, as in the BioSquash system
rather, the ideal summary depends on the user's information needs.
will be studied.
In this line of use, an interesting application would be the integra-
Moreover, in the short term, we plan to extend the method to
tion of the summariser within the PubMed search engine and the
produce query-driven summaries. We will also carefully analyse
use of a preview tool that allows users to visualise the summaries
the structure of biomedical scientific papers to weight the sen-
and quickly choose the documents that best match what they are
tences according to the section in which they appear. Finally, we
looking for without having to read the entire documents. Moreover,
will study the possibility of adapting the system to produce query-
the users' queries may be used to guide the summary generation
driven summaries of EHR.
process and thus to bias the summaries toward their information
needs. To this end, the similarity of each sentence in the document
to the user's query may be computed and added to Eq. a
feature for sentence selection.
This research is funded by the Spanish Government through
Second, extending the method to produce query-driven sum-
the FPU program and the projects TIN2009-14659-C03-01 and TSI
maries will also allow us to deal with more challenging types
of documents, such as EHR. The use of automatic procedures to
summarise the information in EHR is an extremely complex and
subtle issue remains virtually unexplored. First, typing
and orthographic errors are quite frequent in EHR, as is the use
[1] Afantenos SD, Karkaletsis V, Stamatopoulos P. Summarization from medical
of non-standard acronyms and abbreviations. Second, the sum-
documents: a survey. Artificial Intelligence in Medicine 2005;33(2):157–77.
[2] Lau A, Coeira E. Impact of web searching and social feedback on consumer
mariser should be able to capture the clinical relevance of the
decision making: a prospective online experiment. Journal of the American
concepts (i.e., diseases, syndromes, etc.) discussed in the record,
Informatics Association 2008;11:320–31.
regardless of their frequency and their relations with other con-
[3] Hunter L, Cohen KB. Biomedical language processing: perspective what's
beyond PubMed? Molecular Cell 2006;21(5):589–94.
cepts within the record. Third, there is considerable variation in
[4] Reeve LH, Han H, Brooks AD. The use of domain-specific concepts in
the structure of clinical records, so that exploiting such structure
biomedical text summarization. Information Processing and Management
in the summarisation process becomes arduous. Therefore, it is not
feasible to think of the automatic summaries as substitutes for the
[5] Fiszman M, Rindflesch TC, Kilicoglu H. Abstraction summarization for managing
the biomedical research literature. In: Proceedings of the computational lexical
source documents. However, there are other scenarios in which
semantics workshop at HLT-NAACL 2004. 2004. p. 76–83.
such summaries may be useful. Physicians, for instance, often need
[6] Brooks AD, Sulimanoff I. Evidence-based oncology project. Surgical Oncology
to refer to previous patient cases when seeking information for a
Clinics of North America 2002;11:3–10.
[7] Gay CW, Kayaalp M, Aronson AR. Semi-automatic indexing of full text biomedi-
new or untypical case. Given a query that states the physician's
cal articles. In: Friedman CP, Ash J, Tarczy-Hornoch P, editors. Proceedings of the
information need and the set of EHR returned by a search engine,
American Medical informatics association annual symposium. Willow Grove,
each record may be accompanied by an automatically generated
PA, USA: Hanley & Belfus Inc.; 2005. p. 271–5.
summary that highlights the information most relevant to the topic
indicated in the user's query. Moreover, if the EHR follows a stan-
dard structure, the user may indicate which sections should be
[9] Erkan G, Radev D. LexRank: graph-based centrality as salience in text summa-
ignored and which ones should be given more relevance in gener-
rization. Journal of Artificial Intelligence Research 2004;22:457–79.
ating the summary. Each sentence in the record may be weighted
[10] Mihalcea R, Tarau P. TextRank – bringing order into text. In: Proceedings of
according to the section in which it appears simply by adding a
the 2004 conference on empirical methods in natural language processing
(EMNLP). 2004. p. 404–11.
further feature to Eq.
[11] Nelson S, Powell T, Humphreys B. The Unified Medical Language System (UMLS)
project. In: Kent A, Hall CM, editors. Encyclopedia of library and information
science. Marcel Dekker, Inc.; 2002. p. 369–78.
[12] Fleishchman S, Language, medicine D, Schiffirn D, Tannen HE, Hamilton, edi-
tors. The handbook of discourse analysis, vol. 24. Malden, MA, USA: Blackwell
Publishing; 2004. p. 470–502.
In this paper, an efficient approach to biomedical text summari-
[13] Sparck-Jones K. Automatic summarizing: factors directions. In: Mani MT, May-
sation has been presented. The method represents the document
bury I, editors. Advances in automatic text summarization. Cambridge, MA,
USA: The MIT Press; 1999. p. 1–12.
as a semantic graph using UMLS concepts and relations. In this way,
[14] Mani I, Maybury MT, editors. Advances in automatic text summarization. Cam-
it produces a richer representation than the one provided by tradi-
bridge, MA, USA: The MIT Press; 1999.
tional models based on terms. The method has been evaluated on a
[15] Mani I. Automatic summarization natural language processing, vol. 3. Amster-
dam/Philadelphia: John Benjamins Publishing Company; 2001.
collection of 300 scientific biomedical papers from BioMed Central.
[16] Brandow R, Mitze K, Rau LF. Automatic condensation of electronic pub-
It compares favourably with existing approaches, which confirms
lications by sentence selection. Information Processing and Management
that the use of domain-specific knowledge can be very useful in
[17] Luhn HP. The automatic creation of literature abstracts. IBM Journal of Research
automatic summarisation, particularly when dealing with techni-
cal or specialised domains. Three different heuristics for sentence
[18] Edmundson HP. New methods in automatic extracting. Journal of the Associa-
selection have been proposed, each aiming to construct a differ-
tion for Computing Machinery 1969;2(16):264–85.
[19] Kupiec J, Pedersen JO, Chen F. A trainable document summarizer. In: Fox E,
ent type of summary according to the type of information in the
Ingwersen P, Fidel R, editors. Proceedings of the 18th annual international ACM
source that is likely to be included in the summary. It has been
SIGIR conference on research and development in information retrieval. New
found that, when the automatic summaries are evaluated against
York, NY, USA: ACM Press; 1995. p. 68–73.
the authors' abstracts, the best heuristic is the one that selects most
[20] Brin S, Page L. The anatomy of a large-scale hypertextual web search engine.
Computer Networks and ISDN Systems 1998;30(1–7):107–17.
of the information from the main topic of the document, but also
[21] Litvak M, Last M. Graph-based keyword extraction for single-document sum-
includes other secondary or "satellite" information that might be
marization. In: Bandyopadhyay S, Poibeau T, Saggion H, Yangarber R, editors.
relevant to users.
Proceedings of the workshop on multi-source multilingual information extrac-
tion and summarization (Coling 2008). Stroudsburg, PA, USA: ACL Publications;
However, it has been found that the efficiency of the algo-
2008. p. 17–24.
rithm decreases under poor UMLS coverage of concepts in the
[22] Kleinberg J. Authoritative sources in a hyperlinked environment. Journal of the
document to be summarised. Therefore, future work will concen-
[23] Barzilay R, Elhadad M. Using lexical chains for text summarization. In: Proceed-
trate on addressing this problem. Specifically, the feasibility of
ings of the intelligent scalable text summarization workshop (ISTS'97). 1997.
using a general-purpose lexicon (e.g., WordNet to capture the
L. Plaza et al. / Artificial Intelligence in Medicine 53 (2011) 1–14
[24] Yoo I, Hu X, Song I-Y. A coherent graph-based semantic clustering and sum-
[48] Schwartz A, Hearst M. A simple algorithm for identifying abbreviation defini-
marization approach for biomedical literature and a new summarization
tions in biomedical text. In: Jung T, editor. Proceedings of the pacific symposium
evaluation method. BMC Bioinformatics 2007;8(9):1–15.
on biocomputing, vol. 8. Singapore: World Scientific Publishing; 2003. p.
[26] Shi Z, Melli G, Wang Y, Liu Y, Gu B, Kashani M, et al. Question answering
summarization of multiple biomedical documents. In: Kobti Z, Wu D, editors.
[50] PubMed StopWords.
Proceedings of the 20th Canadian conference on artificial intelligence, lecture
notes in computer science 4509. Berlin, Germany: Springer-Verlag; 2007. p.
[51] GATE (Generic Architecture for Text Engineering). [accessed
[27] Miller GA, Beckwith R, Fellbaum C, Gross D, Miller K. Introduc-
[52] Shooshan SE, Mork JG, Aronson AR. National library of medicine. Tech-
nical report. Ambiguity in the UMLS Metathesaurus; 2009 Edition,
[28] Rindflesch TC, Fiszman M. The interaction of domain knowledge and linguistic
structure in natural language processing: interpreting hypernymic proposi-
[53] Humphrey S, Rogers W, Kilicoglu H, Demner-Fushman D, Rindesch T. Word
tions in biomedical text. Journal of Biomedical Informatics 2003;36:462–77.
sense disambiguation by selecting the best semantic type based on journal
[29] Vanderwende L, Suzuki H, Brockett C, Nenkova A. Beyond SumBasic: task-
descriptor indexing: preliminary experiment. Journal of the American Society
focused summarization with sentence simplification and lexical expansion.
for Information Science and Technology 2006;57:96–113.
Information Processing and Management 2007;43(6):1606–18.
[54] Barabasi A, Albert R. Emergence of scaling in random networks. Science
[30] Jonnalagadda S, Tari L, Hakenberg J, Baral C, Gonzalez G. Towards effective
sentence simplification for automatic processing of biomedical text. In: Collins
[55] Levenshtein V. Binary codes capable of correcting deletions, insertions and
M, Narayanan S, Oardandm DW, Vanderwend L, editors. Proceedings of HLT-
reversals. Doklady Akademii Nauk SSSR 1966;163(4):845–8.
NAACL 2009, short papers. ACL Publications, Stroudsburg, PA, USA; 2009. p.
[56] Bossard A, Généreux M, Poibeau T. Description of the LIPN systems at TAC 2008:
summarizing information and opinions. In: Proceedings of the first text analysis
[31] Jonnalagadda S, Gonzalez G. Sentence simplification aids protein–protein inter-
conference (TAC 2008). 2008.
action extraction. In: Rebholz-Schuhmann D, Collier N, Park JC, Wong L, editors.
[57] Bawakid A, Oussalah M. A semantic summarization system: university of Birm-
Proceedings of the 3rd international symposium on languages in biology and
ingham at TAC 2008. In: Proceedings of the first text analysis conference (TAC
medicine. 2009. p. 109–14.
2008). 2008.
[32] Lin J, Wilbur WJ. Syntactic sentence compression in the biomedical domain:
[58] National Institute of Standard and Technology. Document Understanding Con-
facilitating access to related articles. Information Retrieval 2007;10:393–414.
ferences (DUC). [accessed 02.10.10].
[33] Nadkarni PM. Information retrieval in medicine: overview and applications.
[59] Litkowski KC. Summarization experiments in DUC 2004. In: Proceedings of the
Journal of Postgraduate Medicine 2000;46(2):122–66.
2004 document understanding conference (DUC 2004). 2004.
[34] National Library of Medicine. Unified Medical Language System (UMLS).
[60] Radev D, Lam W, Elebi AC, Teufel S, Blitzer J, Liu D, et al. Evaluation challenges
in large-scale document summarization. In: Hinrichs EW, Roth D, editors.
Proceedings of the 41st annual meeting on association for computational lin-
guistics. Stroudsburg, PA, USA: ACL Publications; 2003. p. 375–82.
[61] Mani I. Summarization evaluation: an overview. In: Adachi J, Kando N, editors.
Proceedings of the 2nd NTCIR workshop on research in Chinese & Japanese text
retrieval and text summarization. Tokyo, Japan: National Institute of Informat-
[38] International Health Terminology Standards Development Organisation.
[62] Sparck-Jones K, Galliers J. Evaluating natural language processing systems: an
SNOMED-CT. [accessed 02.10.10].
analysis and review. Berlin, Germany: Springer-Verlag; 1995.
[39] National Library of Medicine. MetaMap Portal.
[63] Tratz S, Hovy E. Summarization evaluation using transformed Basic Elements.
In: Proceedings of the text analysis conference (TAC). 2008.
[40] Aronson AR. Effective mapping of biomedical text to the UMLS Metathesaurus:
[64] Giannakopoulos G, Karkaletsis V, Vouros G, Stamatopoulos P. Summarization
the MetaMap program. In: Bakken S, editor. Proceedings of the American medi-
system evaluation revisited: N-gram graphs. ACM Transactions on Speech and
cal informatics association annual symposium. Willow Grove, PA, USA: Hanley
Language Processing 2008;5(3):1–39.
& Belfus Inc.; 2001. p. 17–21.
[65] Pitler E, Nenkova A. Revisiting readability: a unified framework for predicting
[41] Eck M, Vogel S, Waibel A. Improving statistical machine translation in the
text quality. In: Lapata M, Ng HT, editors. Proceedings of the 2008 conference
medical domain using the Unified Medical Language System. In: Proceedings
on empirical methods in natural language processing. Stroudsburg, PA, USA:
of the 20th international conference on computational linguistics. 2004. p.
ACL Publications; 2008. p. 186–95.
[66] Vadlapudi R, Katragadda R. Quantitative evaluation of grammaticality of sum-
[42] Overby CL, Tarczy-Hornoch P, Demner-Fushman D. The potential for automated
maries. In: Gelbukh A, editor. Proceedings of the 11th international conference
question answering in the context of genomic medicine: an assessment of exist-
on computational linguistics and intelligent text processing (CICLing 2010), lec-
ing resources and properties of answers. BMC Bioinformatics 2009;10(Suppl. 9
ture notes in computer science 6008. Berlin, Germany: Springer-Verlag; 2010.
p. 736–47.
[43] Aronson AR, Rindflesch TC. Query expansion using the UMLS Metathesaurus.
[67] Lin C-Y. ROUGE: a package for automatic evaluation of summaries. In: Moens
In: Masys DR, editor. Proceedings of the American medical informatics associ-
M-F, editor. Proceedings of workshop on text summarization branches out,
ation annual symposium. Willow Grove, PA, USA: Hanley & Belfus Inc.; 1997.
post-conference workshop of ACL. Stroudsburg, PA, USA: ACL Publications;
2004. p. 74–81.
[44] Plaza L, Díaz A. Retrieval of similar electronic health records using UMLS con-
[68] Lin C-Y. Looking for a few good metrics: automatic summarization evaluation
cept graphs. In: Hopfe CJ, Rezgui Y, Métais E, Preece A, Li H, editors. Proceedings
– how many samples are enough? In: Adachi J, Kando N, editors. Proceedings
of the 15th international conference on applications of natural language to
of the 4th NTCIR workshop on research in information access technologies
information systems (NLDB 2010), lecture notes in computer science 6177.
information retrieval, question answering and summarization. Tokyo, Japan:
Berlin, Germany: Springer-Verlag; 2010. p. 296–303.
National Institute of Informatics; 2004.
[45] Plaza L, Díaz A, Gervás P. Automatic summarization of news using WordNet
[69] Saggion H. SUMMA: a robust and adaptable summarization tool. Revue Traite-
concept graphs. In: Weghorn H, Roth J, Isaías P, editors. Proceedings of the
ment Automatique des Langues 2008;49(2):103–25.
IADIS international conference informatics. Lisbon, Portugal: IADIS Press; 2009.
[70] Microsoft Corporation. Microsoft Office online: automatically summarize
[46] Plaza L, Lloret E, Aker A. Improving automatic image captioning using text
summarization techniques. In: Sojka P, et al, editors. Proceedings of the
[71] Hovy EH. Automated text summarization. In: Mitkov R, editor. The Oxford
13th international conference on text, speech and dialogue, lecture notes
handbook of computational linguistics. Oxford, United Kingdom: Oxford Uni-
in artificial intelligence 6231. Berlin, Germany: Springer-Verlag; 2010. p.
versity Press; 2005. p. 583–98.
[72] Smith CA. Information retrieval in medicine: the electronic medical record as a
[47] BioMed Central Corpus.
new domain. In: Proceedings of the American society for information science
and technology, vol. 43, no. 1. 2006. p. 1–30.
Source: http://nlp.uned.es/~lplaza/papers/AIIM2011.pdf
Environmental Claims on Product Packaging: French Packaging Council Views and Recommendations French Packaging Council (CNE) – All rights reserved – November 2012 Table of contents 1. Summary 2. Context 3. Objectives 4. Regulations and standards
Guidelines for the Management of Anticoagulant and Anti-Platelet Agent Associated Bleeding Complications in Purpose: To be used as a common tool for all practitioners involved in the care of patients who present with bleeding problems related to use of anticoagulant and anti-platelet agents. The guidelines were developed to represent available evidence from the literature. It is recognized that there may be instances where interventions not identified in these guidelines may be indicated. These guidelines are not meant to supersede the clinical judgment of the treating physician. For purposes of organization, the guidelines are arranged in a linear order from initial interventions through definitive care. The clinician should recognize that treatment phases may overlap and interventions will occur concurrently.